Demo
Try entering a query and looking at the results! Wait a few seconds after entering your query, it might take a bit to load and update.
Explanation
I’ve had a lot of time on my hands recently (due to COVID-19). If you are an avid search engine user (you almost certainly are), then you’ll likely have seen a panel on the side of your search results that looks like this (this screenshot is of Google, but feel free to try these with your search engine of choice):
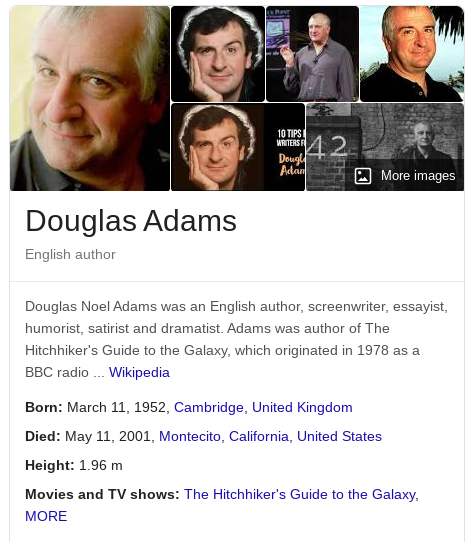
But that’s not all! If we search for some specific fact about Douglas Adams, such as his height, Google is able to figure it out and tell it to us:

How is Google able to figure this out? Google has a database with a bunch of facts in it, called their “knowledge graph”. Those facts are sometimes called triples, since they have three parts: for the above example, a subject: Douglas Adams, a predicate: height, and a object: 1.96 meters.
Aside: You might also hear about quads: they’re like triples, but the 4th part is the context, which identifies what database/graph the quad is a part of.
Google isn’t the first or only company to have a knowledge graph, however. Wolfram Alpha also has one. Bing also has one. Both are able to tell you Douglas Adams’s height. So, where do they get all of their data from?
While every knowledge graph has it’s differences (Wolfram Alpha’s is a lot more curated, for example), many of the facts in Google and Bing appear to be sourced from Wikidata. I could write a lot about Wikidata’s data model, but the simplifed version is that it’s a triplestore that anybody can edit, similar to Wikipedia. In fact, it’s run by the same Wikimedia Foundation that runs Wikipedia, and it’s possible with some template magic to include Wikidata facts into Wikidata. Triples, or statements as Wikidata refers to them, can also have references associated with them to identify what sources support a claim, and qualifiers to qualify a claim and add more detailed (for example, when a claim started being true).
Note: Wikidata isn’t the only source! I’m pretty sure Google uses DBpedia, and there are probably some proprietary datasets they pay for.
All of the structured data in Wikidata is licensed under CC0, which puts it in the public domain. As such, there’s no easy way to tell if Google uses Wikidata, since they don’t say anywhere, nor are the required to. There’s a hard way to tell, though! Comparing Google’s data to Wikidata shows that Google’s knowledge graph almost always has the exact same data as Wikidata. Also, Google’s knowledge graph occasionally reflects mistakes in Wikidata.
So, how can we access the data in Wikidata? The two main ways are the API, and the entity dumps. Wikidata’s API allows you programatically query and edit Wikidata. The entity dumps are just really big files that contain every statement in Wikidata, created around weekly. The all dump contains all statements in Wikidata, and is really big - over 2TB uncompressed (well that’s just an estimate, I don’t have enough storage to decompress the thing and find out the exact amount). The truthy dump is smaller, and just contains truthy statements, which are the most current/correct statements (Wikidata doesn’t just store statements that are currently true, but also things that have been true in the past, and things that are known to be wrong so bots don’t incorrectly re-add data known to be incorrect). truthy is just over 1TB in size uncompressed.
The data is available in multiple formats, but I use the JSON one, since it’s easier to parse in work with. The data dump is processed, and turned into a bunch of files, one for each entity. When data is needed about an entity, it’s file is just read from the file system. I’m effectively using the file system as a database. Also, it turns out that not all filesystem formats are able to handle millions of file in a directory very well. After my first failed attempt with ext4, I tried again with XFS, which works quite well (not that I’ve compared it to anything else).
When you type a query into the knowledge panel generator I showed at the beginning of the post, it has to search through tens of millions of possible entities’ names and aliases. The backend is implemented entirely in Rust. Optimizing this to work on a VPS without much RAM or compute power was a challenge. I’ve ended up using Rust’s BTreeMap to store all entity names and aliases into one big binary tree. However, this posed a problem at first: Wikidata items don’t all have unique names and aliases. The only unique identifier for a Wikidata item is it’s unique ID (Q219237, for example). There are many entities in Wikidata that share the same name, such as people who happen to have the same full name, or Q89 (apple, the fruit) and Q213710 (Apple, the record label). Since a BTreeMap can’t have two identical keys (they would just overwrite each other), I use a key of (String, usize). That’s a tuple where the first element is the normalized name of the entity, and the second is a unique number for each item.
When a query is made, I lookup the range of everything from the query text to the query with ZZ at the end. I’m effectively doing a prefix search across the binary tree.
Once all possible options are found, I try to generate infoboxes for all of them. Sometimes it fails to generate an infobox (for instance, because there are no triples that it knows how to handle), but otherwise it just inserts all of the triples it can handle into a box. The social media links just check against a few properties, and use SVG logos.
Of course, my knowledge panel isn’t perfect! It currently doesn’t display all of the parts of a location (it just does “London”, instead of “London, England”), and is missing support for many Wikidata properties. Hopefully I’ll be able to improve it in the future!
Thanks for reading! If you have any questions, comments, concerns, or inquiries feel free to email them to cogzap@speakscribe.com.
By the way, I wrote this post with Roam, it’s a pretty neat tool.
